Categories
Archives
The IPTC has released a comprehensive set of sports controlled vocabularies as a supplement to the SportsML 3.0 sports-data interchange format, which was released in July 2016. These controlled vocabularies (CVs) are in the format of NewsML-G2 NewsML-G2 Knowledge Items plus RDF variants and are available on IPTC’s CV server at http://cv.iptc.org/newscodes.

There are 113 CVs representing such core sports concerns such as event and player status, as well as specialized lists for 11 sports (basketball, soccer, rugby, American football, etc.) for statistics, player positions, scoring types, etc.
“The SportsML 3.0 standard’s semantic tech capabilities are improved greatly by the new controlled vocabularies,” said Trond Husø, system developer for Norwegian news agency NTB, one of the early adopters of SportsML 3.0. “Data can be easily imported, structured, and stored.”
“When building a sports app you spend a lot of prep time defining your terms and building a schema,” said Paul Kelly, news technology consultant and lead for IPTC’s Sports Content Working Group. “By using SportsML 3.0, there is no need to reinvent the wheel.”
“You consider things such as ‘What sort of results and stats do we need?’ and ‘How will our system handle interrupted matches?’ IPTC’s vocabularies can get you on your way because they properly define in a standard format almost all the terminology you would use in a sports application: Everything from “goals-scored” to a full enumeration of status codes for sports events,” Kelly said.
For the Summer 2016 Olympics, NTB acquired the rights to distribute the results and data from the International Olympics Committee’s Olympic Data Feed (ODF). NTB then transformed ODF to SportsML 3.0, and then to NITF3.2. “Using SportsML to structure the ODF’s data is a broad and comprehensive solution to approaching all sports and competitions worldwide,” said Husø, who is also a member of IPTC’s Sports Content Working Group. “SportsML is now a truly flexible and universal format that can incorporate multiple vendor codes and still provide a defense against vendor lock-in.”
“Terms defined in another format such as ODF can easily live beside SportsML terms – as well as any other proprietary format – so that an organisation can build a repository of knowledge of all the different sports-data formats,” Kelly said.
Another advantage to the new SportsML 3.0 standard is that if new concepts are added to a sports vocabulary or modified in it, the data model and the XML Schema don’t change; they stay stable. It also supports all languages for the concept labels.
“A great feature is that we can translate the definitions to Norwegian – without changing or breaking the vocabulary,” said Husø. “If we were to distribute internationally, our domestic receivers could look up the definitions in Norwegian, while the international ones could use the English term.”
IPTC’s SportsML 3.0 standard underwent a major upgrade from version 2.2, after 12 years of evolution since its first version. The new standard incorporates contribution from sports experts in 12 countries. Its flexible core covers all major sports and events in most news reporting.
Other early adopters of SportsML 3.0 include Univision and the British Press Association in its new multi-sport API. Its major features include:
- compliance with IPTC’s NewsML-G2 standard
- a flexible core that covers all major sports and events in most news reporting
- plugins for detailed stats in 10+ sports
- a more flexible tournament model
- schedules, scores, standing, statistics, etc.
- choices between specific and generic terms
- controlled vocabularies, semantic tech capabilities
- schema redesign
- many samples and tool support.
Tool support for SportsML 3.0 includes 45 samples from 11 different sports and events, including both classic and SportsML-G2 examples, and both generic and specific examples.
The vocabularies will be maintained by IPTC for future expansion; new sports and terms can be added.
For more information on SportsML 3.0:
SportsML 3.0 Standard, including Zip package
SportsML 3.0 Specification Documents
NewsML-G2 Standard
Contact: Trond Husø @trondhuso, Trond.Huso@ntb.no
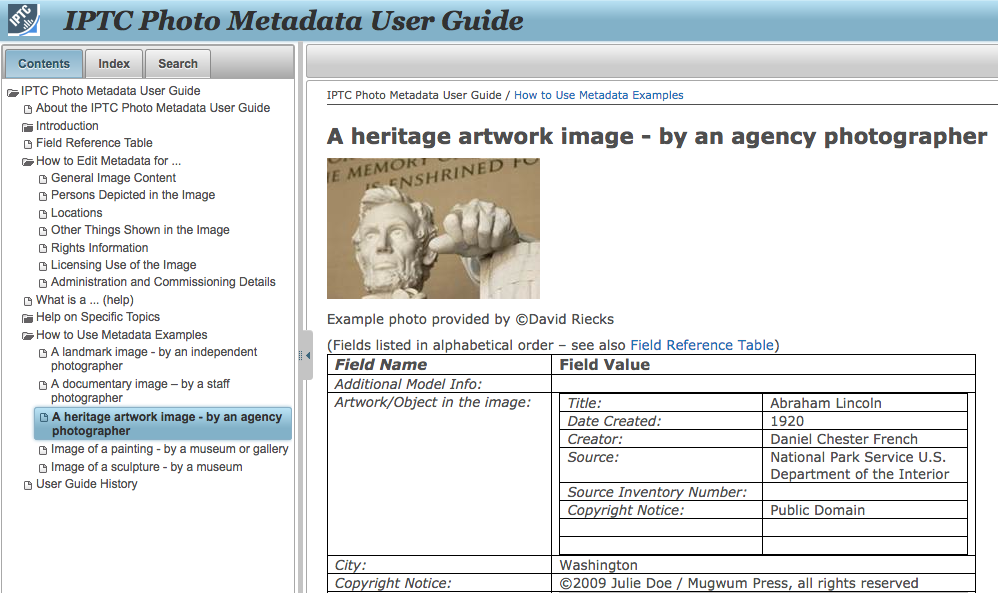
IPTC has published an updated Photo Metadata User Guide, for photographers, photo editors and professionals responsible for in-house metadata workflows, including digital asset management (DAM) systems.
Based on IPTC’s widely used Photo Metadata Standard, the new User Guide contains practical information regarding photo metadata – from photographers familiarizing themselves with basics, to managers in related businesses who have a deeper understanding of implementation of standards and metadata.
A key use of metadata is to describe the content of an image, location and rights information; the guide groups metadata fields according to information types. “The User Guide will help when deciding where metadata should be put about a certain topic, and what data should or should not be filled into a specific field,” said Michael Steidl, managing director of IPTC, and lead of IPTC’s Photo Metadata Working Group.
IPTC sets the industry standard for administrative, descriptive, and copyright information about images. The IPTC Photo Metadata Standard, supported by many software applications, is the most widely used standard because of its universal acceptance among photographers, distributors, news organisations, archivists, and developers.
The Photo Metadata User Guide walks users through the major groups of metadata, and for each IPTC field contained within each, it provides short guidelines on the use and semantics.
The first section of the guide outlines practical use for a basic understanding of applying photo metadata, and may be most helpful to photographers becoming familiar with adding it to their photos for the first time. Photo metadata is key to protecting photographers’ images, including copyright and licensing information online.
The User Guide addresses typical questions such as:
- What is a minimum set of fields to be used?
- How is metadata preserved?
Five examples of metadata for independent, staff, and agency photographers plus images of artwork are given.
Photo metadata is also essential for managing digital assets. Detailed and accurate descriptions about images ensure they can be easily and efficiently retrieved via search, by users or machine-readable code. This results in smoother workflow within organisations, more precise tracking of images, and potential for licensing opportunities.
For professionals responsible for in-house photo metadata workflows and DAM systems, all IPTC metadata fields in the User Guide have been grouped by topic for easy reference: general description, persons, locations, things shown, rights and licensing information, and administrative data.
The User Guide does not focus on the user interface of a specific software, and will be updated regularly to include more details.
For questions about the Photo Metadata User Guide or about becoming involved in IPTC’s work: Contact us.
Twitter: @IPTC
LinkedIn: IPTC
IPTC is looking for software developers to design, develop, document and test EXTRA, an open source rules-based classification engine for news. First preference will be given to applications received by 21st October 2016, and review will continue until the positions are filled.
“Classification” means assigning one or more categories to the text of a news document. Rules-based classifiers use a set of Boolean rules, rather than machine-learning or statistical techniques, to determine which categories to apply.
EXTRA is the EXTraction Rules Apparatus, a multilingual open-source platform for rules-based classification of news content. IPTC was awarded a grant of €50,000 from the first round of Google’s Digital News Initiative Innovation Fund to build and freely distribute the initial version of EXTRA. DNI granted IPTC €50,000 for the entire project.
We are working with news providers to supply sets of news documents and with linguists to write rules to classify the documents. IPTC is looking for qualified developers to create the rules engine to accurately and efficiently categorize the documents using the rules.
Please consult this page for more information and to let us know if you’re interested in being considered.
Questions? Contact us.
Twitter: @IPTC
LinkedIn: IPTC
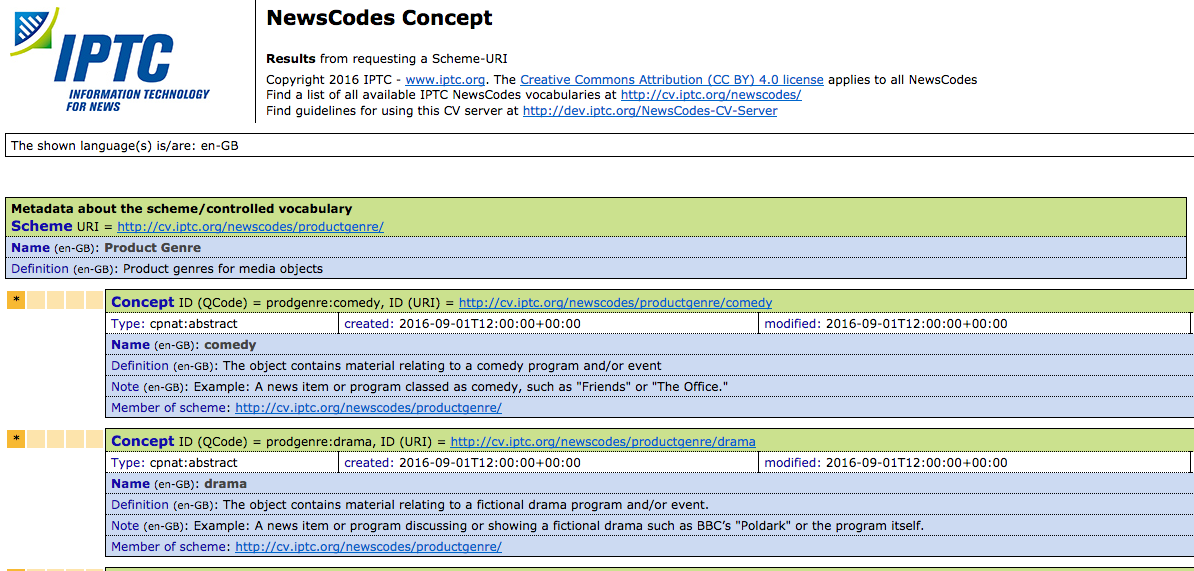
The IPTC NewsCodes family of controlled vocabularies has a new member: Product Genre.
The Product Genre vocabulary was developed at the request of the broadcast industry. A broad category of terms was needed – one that specifies the kind of content by media product type – in addition to metadata that describes the content. The Product Genre scheme includes terms such as comedy, drama, entertainment, travel and sport.
NewsCodes are sets of concepts created and maintained by the IPTC, also known as controlled vocabulary or taxonomy. They are assigned as metadata values to news objects like text, photographs, graphics, audio and video files and streams. This allows for a consistent coding of news metadata across news providers and over the course of time.
The Product Genre vocabulary was an idea initiated by Andy Read, IPTC delegate and BBC’s Service Development and Delivery Manager for News, who has worked with IPTC for more than 20 years. This was based on feedback from broadcast members that highlighted the value of the forum engagements in driving the progression of the data set.
“There was a need to extend the breadth of the controlled vocabularies,” said Read. “The new Product Genre vocabulary codes describe the type of program itself, and help to broaden the program to a wider audience and general TV/broadcast industry.”
NewsCodes vocabularies can be very specific. A broader category like Product Genre allows identification of an entire broadcast program or package – not just smaller segments. For example, a longer 60-minute program overview about Syria’s war can be coded according to Product Genre – supplemented by metadata specific to a minute-long clip about a possible chemical attack, in the context of the larger news program.
“The Product Genre needed to be added to help facilitate use of these codes with IPTC’s NewsML-G2 standards,” said Read.
The new Product Genre vocabulary is also beneficial on the business side, said Jennifer Parrucci, senior taxonomist for the New York Times.
“Advertising is often sold based on the type of program – not necessarily subject tags or more specific terms,” Parrucci said. “The Product Genre vocabulary identifies advertising opportunities at a more comprehensive level.”
The IPTC NewsCodes Working Group, chaired by Parrucci, collaborated to define the vocabulary terms, based on concrete examples and actual TV programs. For each Concept identifier and name, a definition is listed. The notes section gives an example of what that Concept describes, for clarity and accurate use.
Any NewsCode provided by the IPTC can be used at any stage of a news workflow, without any royalty fee. But if one includes IPTC NewsCodes into an application, the intellectual property and the copyright of the IPTC must be explicitly attributed.
More information:
Product Genre terms and definitions
IPTC NewsCodes and other vocabularies
Tree diagrams: IPTC NewsCodes and groups.
Questions? Contact us.
Twitter: @IPTC
LinkedIn: IPTC
Interesting stats and info about the International Press Telecommunications Council’s technical standards for exchange of news information:
 1.) The International Press Telecommunications Council publishes 14+ technical standards that are intended for the business-to-business exchange of news among news agencies, other news providers and publishers.
1.) The International Press Telecommunications Council publishes 14+ technical standards that are intended for the business-to-business exchange of news among news agencies, other news providers and publishers.
2.) At least one or two IPTC standards are in use at virtually every newspaper and news web site in the world.
Publishers use IPTC standards to save money and improve the ability of their news products to be used by customers.
3.) IPTC standards for news exchange are available for downloading at no cost – and there are no royalties or fees.
The only source of income for IPTC is membership dues. Membership currently consists of more than 50 organizations and individuals worldwide.
4.) All IPTC standards are designed to be independent of any specific language.
Although our publications are written in English and meetings are conducted in English, every recent standard is usable by any written language that is supported by Unicode.
5.) More than 70 software applications support IPTC Standards.
Software developers seamlessly integrate IPTC standards into their products – often in subtle ways that are not obvious to customers.
More information:
IPTC.org
IPTC Standards
Contact: Michael Steidl, mdirector@iptc.org

It’s an Olympic year for IPTC’s SportsML 3.0 standard, the recently released update to the most comprehensive tech-industry XML format for sports data.
Norsk Telegrambyrå (NTB), in Norway, is one of the first news organizations to implement SportsML 3.0, in time for the 2016 Games in Rio.
“We figured, why not use the latest technology available?” said Trond Husø, system developer for NTB, who worked on the standard’s update, released in July. “SportsML 3.0’s use of controlled vocabularies for sport competitions and other subjects now provides many benefits, including more flexibility. Storing results is also more convenient.”
SportsML 3.0 is the ideal structure and back-end solution used by many major news organizations because it is the only open global standard for scores, schedules, standings and statistics. “It saves the time and cost of developing an in-house structure,” said Husø, also a member of IPTC’s Sports Content Working Party.
The Rio Games, which will host about 10,500 athletes from 206 countries, for 17 days and 306 events, are revolutionary for big data and new approaches for managing it. For the first time, the International Olympic Committee (IOC) used cloud-based solutions for work processes including volunteer recruitment and accreditation.
And consider the experimental technologies and apps launched by key broadcasters and Olympic Broadcasting Services, the Olympic committee responsible for coordinating TV coverage of the Games: virtual reality footage, online streaming, automated reporting, drone cameras, and Super-High Vision, which is supposedly 16 times clearer than HD.
Billions of Olympic spectators worldwide have naturally come to expect real-time results and accurate scores to be delivered to them, with a side of historical perspective. All with little thought as to how the information reaches the public, be it via tickers on websites, graphic stats on TV screens, or factoids offered by commentators.
Schedules, competitors’ names, bio information, times, rankings, medalists – how does all of this data get served up so quickly and uniformly among networks and news services? And how does it get integrated into existing news systems, namely SportsML 3.0?
It starts with the IOC – the non-profit, non-governmental body that organizes the Olympic Games and Youth Olympic Games. They act as a catalyst for collaboration for all parities involved, from athletes, organiser committees, and IT, to broadcast partners and United Nations agencies. The IOC generates revenue for the Olympic Movement through several major marketing efforts, including the sale of broadcast rights.
The IOC produces the Olympic Data Feed (ODF), the repository of live data about past and current games. The IOC is responsible for communicating the official results; they use the specific ODF format for their ODF data.
Paying media partners sign a licensing agreement to use ODF, to report on results through their own channels, and build new apps, services and analysis tools.
The goal of ODF is to define a unified set of messages valid for all sports and several different news systems – so that all partners are receiving the same data, at the same time. It was introduced for the Vancouver Games in 2010 and is an ongoing development effort.
According to the IOC’s website, ODF plays the part of messenger. From a technical standpoint, the data is machine-readable. ODF sends sports information from the moment it is generated to its final destination via Extensible Markup Language (XML). XML, a framework for storing metadata about files, is a flexible means to electronically share structured data via the Internet, as well as via corporate networks.
IPTC’s SportsML 3.0 easily imports data from ODF. Using SportsML to structure the ODF’s data is a broad and comprehensive solution to approaching all sports and competitions worldwide. ODF has identifiers for sports and awards (gold, silver, and bronze medals) executed at the Olympic Games; sports outside of ODF are identified by vocabulary terms of SportsML.
“SportsML 3.0 provides one structure for the data for developers to work in,” said Husø. “The structure will be the same, even if there are changes to ODF in future Olympic Games; the import and export process of the data will not change.”
Among content providers that use SportsML (various versions) are NTB, AP mobile (USA), BBC (UK), ESPN (USA), PA – Press Association (UK), Univision (USA, Mexico), Yahoo! Sports (USA), and Austria Presse Agentur (APA) (Austria), and XML Team Solutions (Canada).
SportsML 3.0 is based on its parent standard, NewsML-G2, the backbone of many news systems, and a single format for exchanging text, images, video, audio news and event or sports data – and packages thereof. SportsML 3.0 is fully compatibility with IPTC G2 structures.
For more information on SportsML 3.0:
SportsML 3.0 Standard, including Zip package
SportsML 3.0 Specification Documents, IPTC’s Developer site
NewsML-G2 Standard
Contact: Trond Husø @trondhuso, Trond.Huso@ntb.no
 The NewsCodes Working Group of IPTC has completed mapping of the top two levels of hierarchical terms of Media Topics to Wikidata.
The NewsCodes Working Group of IPTC has completed mapping of the top two levels of hierarchical terms of Media Topics to Wikidata.
Media Topics is an IPTC standard – a 1,100-term taxonomy with a focus on categorizing text. Released in 2010 as a development based on the IPTC Subject Codes, use of Media Topics is free and available in different formats. They can be viewed on the IPTC Controlled Vocabulary server, or in a user-friendly tree hierarchy tool.
IPTC creates and maintains taxomonies and controlled vocabularies – to assign terms as metadata values to news objects like text, photographs, graphics, audio and video files and streams. This allows for a consistent coding of news metadata across news providers, over the course of time.
“The idea of semantic mapping and being involved in a linked data initiative like Wikidata is a natural step for IPTC,” said Jennifer Parrucci, chair of the IPTC NewsCodes Working Group and senior taxonomist for The New York Times. “When linking an existing taxonomy to another, Wikidata serves as a central point of reference.”
Wikidata is a free, collaborative, multilingual knowledge base that can be read and edited by both humans and machines. It provides centralized storage for an access to structured data for all Wikimedia projects, as well as for use on external websites.
In total about 100 mappings from Media Topics to Wikidata have been manually applied. The mappings use SKOS mapping relationships.
Media Topics began with the Subject Codes vocabulary and extended the tree from 3 to 5 levels and reused the same 17 top-level terms. The lower-level terms have been revised and rearranged. Each Media Topic provides a mapping back to one of the Subject Codes.
More information:
Media Topics Page, IPTC.org
IPTC Controlled Vocabulary server
Guidelines
Tree Hierarchy Tool
News CodesSubject Codes
Questions? Contact us.
The International Press Telecommunications Council (IPTC) is close to finalizing a new recommendation for video standards: the IPTC Video Metadata Hub.
The Video Metadata Working Group, which is comprised of members worldwide from news organisations, vendors and experts in the metadata field, is planning to vote on a recommendation of the Video Metadata Hub (VMD Hub) at the IPTC Autumn Meeting, 24 – 26 October 2016, in Berlin. The final Draft #4 has been published for a last round of reviews: http://dev.iptc.org/Video-Metadata.
Because there are several different existing standards for video – for compressing video and audio, file formats and different schemas of metadata properties – IPTC is presenting a “hub” recommendation that covers many use cases and exchange of metadata over multiple standards.
The VMD Hub is comprised of a single set of video metadata properties, which can be expressed by multiple technical standards (namely XMP for metadata embedded into binary video files, and EBU Core for non-embedded metadata stored in sidecar files). These properties can be used for describing the visible and audible content, rights data, administrative details and technical characteristics of a video.
Likewise, the VMD Hub supports workflow, exchange of metadata, and search functions across other existing standards, and will include mapping to Apple Quicktime, PBCore, MPEG7 and Schema.org, and perhaps more in the future.
“Users of videos of different standards told IPTC they need a common ground in metadata for efficient workflows,” said Michael Steidl, Managing Director of IPTC. “This is what we deliver now with the Video Metadata Hub.”
The IPTC Autumn Meeting will feature a Video Day on 25 October. In addition to the presentation about the VMD Hub, speakers from video makers, video suppliers, video content publishers and system vendors will discuss how video workflows can be improved.
For information about attending the IPTC Autumn Meeting and Video Day, contact us.
IPTC has secured funding and the foundation for language and technical requirements for its EXTRA Project – a rules-based classification system, as reported at IPTC’s Summer Meeting 2016 by Stuart Myles, project lead and IPTC Chairman of the Board.
EXTRA is the EXTraction Rules Apparatus, a multilingual open-source platform for rules-based classification of news content. EXTRA will allow newsrooms to automatically annotate news content with high-quality metadata subjects using a predefined set of rules. IPTC was awarded a grant from the first round of Google’s Digital News Initiative Innovation Fund to build and freely distribute the initial version of EXTRA.
The EXTRA project team has delivered a road map for the project to Google’s Digital News Initiative, and are finalizing their plans for language requirements and rules, as well as technical requirements and licensing. IPTC will approach existing open source communities, linguists and programmers to facilitate development.
For easy adoption and consistency in the news industry, IPTC is creating rules for tagging documents with its industry standard Media Topics vocabulary, used widely by publishers. IPTC plans to provide example rules for at least two of the languages supported by Media Topics: Arabic, English, French, German and Spanish.
“For small to medium size publishers who are dissatisfied with hand-tagging their content or grappling with complex machine-learning tools, EXTRA is an open-source news classification engine that will let you easily apply rich metadata to breaking news content,” said Myles. “Unlike manual techniques, which can be slow and inconsistent, or traditional statistical methods, which aren’t suitable for breaking news, EXTRA’s rules-based classification will provide fast, consistent and relevant metadata to enrich search, advertising and content analytics.”
IPTC invites other parties to join the development of the EXTRA project. To get involved, contact Myles at chair@iptc.org.
Related Links:
For developers: http://dev.iptc.org/Topic-EXTRA
Road map and project description: https://iptc.github.io/extra/
Press Release
The International Press Telecommunications Council (IPTC) will use a grant from the first round of Google’s Digital News Initiative Innovation Fund to build and freely distribute an initial version of EXTRA: The EXTraction Rules Apparatus, a multilingual open-source platform for rules-based classification of news content.
EXTRA will be a classification system for annotating news documents with high-quality subject tags. Such tags will allow publishers to deliver a variety of valuable services including content recommendations, improved advertising targeting and subject-specific content streams, such as alerts and topic pages.
“By creating a freely available rules-based classification engine, IPTC will help publishers to enhance their content with all sorts of metadata services, including enriched search, intelligent recommendations and precise analytics,” said Stuart Myles, chairman of IPTC.
EXTRA will provide news publishers with several key capabilities: the ability to automatically categorize documents by subject (for example, terrorism, sports, names of celebrities); the ability to author classification rule sets tailored to existing taxonomies; and the ability to classify documents using the industry standard IPTC Media Topics taxonomy. Taxonomies are used by many news organizations to classify their content. Classification is used in various ways, including improved online news navigation by grouping and linking, to organize editorial workflows and to enrich search.
So that EXTRA is immediately useful to the news publishing community, IPTC will create different suites of rules in two languages for classifying news documents into the IPTC Media Topics taxonomy, an industry-standard taxonomy used by several leading news providers.
“We hope that the EXTRA project will support a migration in the news publishing community towards a common industry-wide open source platform,” said Michael Steidl, managing director of IPTC. “We believe that a freely available document classification platform will provide great benefit to small-to-medium sized publishers.”
IPTC invites other parties to join the development of EXTRA.
Contact office@iptc.org to learn more, including how you can get involved.
Over €27m has been offered by Google to 128 projects, large and small, from 23 countries across Europe – each designed to advance innovation in the news industry. DNI is a collaboration between Google and news publishers in Europe to support high quality journalism and encourage a more sustainable news ecosystem through technology.
About IPTC: The IPTC, based in London, brings together the world’s leading news agencies, publishers and industry vendors. It develops and promotes efficient technical standards to improve the management and exchange of information between content providers, intermediaries and consumers. The standards enable easy, cost-effective and rapid innovation. Visit www.iptc.org and follow on Twitter: @IPTC