Categories
Archives
 The IPTC is happy to announce the latest version of our guidance for mapping between photo metadata standards.
The IPTC is happy to announce the latest version of our guidance for mapping between photo metadata standards.
Following our publication of IPTC’s rules for mapping photo metadata between IPTC, Exif and schema.org standards in 2022, the IPTC Photo Metadata Working Group has been monitoring updates in the photo metadata world.
In particular, the IPTC gave support and advice to CIPA while it was working on Exif 3.0 and we have updated our mapping rules to work with the latest changes to Exif expressed in Exif 3.0.
As well as guidelines for individual properties between IPTC Photo Metadata Standard (in both the older IIM form and the newer XMP embedding format), Exif and schema.org, we have included some notes on particular considerations for mapping contributor, copyright notice, dates and IDs.
The IPTC encourages all developers who previously consulted the out-of-date Metadata Working Group guidelines (which haven’t been updated since 2008 and are no longer published) to use this guide instead.
 On Tuesday 12 November 2023, a group of news, journalism and media organisations released what they call the “Paris Charter on AI and Journalism.” Created by 17 organisations brought together by Reporters sans frontières and chaired by journalist and Nobel Peace Prize laureate Maria Ressa, the Charter aims to give journalism organisations some guidelines that they can use to navigate the intersection of Artificial Intelligence systems and journalism.
On Tuesday 12 November 2023, a group of news, journalism and media organisations released what they call the “Paris Charter on AI and Journalism.” Created by 17 organisations brought together by Reporters sans frontières and chaired by journalist and Nobel Peace Prize laureate Maria Ressa, the Charter aims to give journalism organisations some guidelines that they can use to navigate the intersection of Artificial Intelligence systems and journalism.
The IPTC particularly welcomes the Charter because it aligns well with several of our ongoing initiatives and recent projects. IPTC technologies and standards give news organisations a way to implement the Charter simply and easily in their existing newsroom workflows.
In particular, we have some comments to offer on some principles:
Principle 3: AI SYSTEMS USED IN JOURNALISM UNDERGO PRIOR, INDEPENDENT EVALUATION
“The AI systems used by the media and journalists should undergo an independent, comprehensive, and thorough evaluation involving journalism support groups. This evaluation must robustly demonstrate adherence to the core values of journalistic ethics. These systems must respect privacy, intellectual property and data protection laws.”
We particularly agree that AI systems must respect intellectual property laws. To support this, we have recently released the Data Mining property in the IPTC Photo Metadata Standard which allows content owners to express any permissions or restrictions that they apply regarding the use of their content in Generative AI training or other data mining purposes. The Data Mining property is also supported in IPTC Video Metadata Hub.
Principle 5: MEDIA OUTLETS MAINTAIN TRANSPARENCY IN THEIR USE OF AI SYSTEMS.
“Any use of AI that has a significant impact on the production or distribution of journalistic content should be clearly disclosed and communicated to everyone receiving information alongside the relevant content. Media outlets should maintain a public record of the AI systems they use and have used, detailing their purposes, scopes, and conditions of use.”
To enable clear declaration of generated content, we have created extra terms in the Digital Source Type vocabulary to express content that was created or edited by AI. These values can be used in both IPTC Photo Metadata and IPTC Video Metadata Hub.
Principle 6: MEDIA OUTLETS ENSURE CONTENT ORIGIN AND TRACEABILITY.
“Media outlets should, whenever possible, use state-of-the-art tools that guarantee the authenticity and provenance of published content, providing reliable details about its origin and any subsequent changes it may have undergone. Any content not meeting these authenticity standards should be regarded as potentially misleading and should undergo thorough verification.”
Through IPTC’s work with Project Origin, C2PA and the Content Authenticity Initiative, we are pushing forward in making provenance and authenticity technology available and accessible to journalists and newsrooms around the world.
In conclusion, the Charter says: “In affirming these principles, we uphold the right to information, champion independent journalism, and commit to trustworthy news and media outlets in the era of AI.”

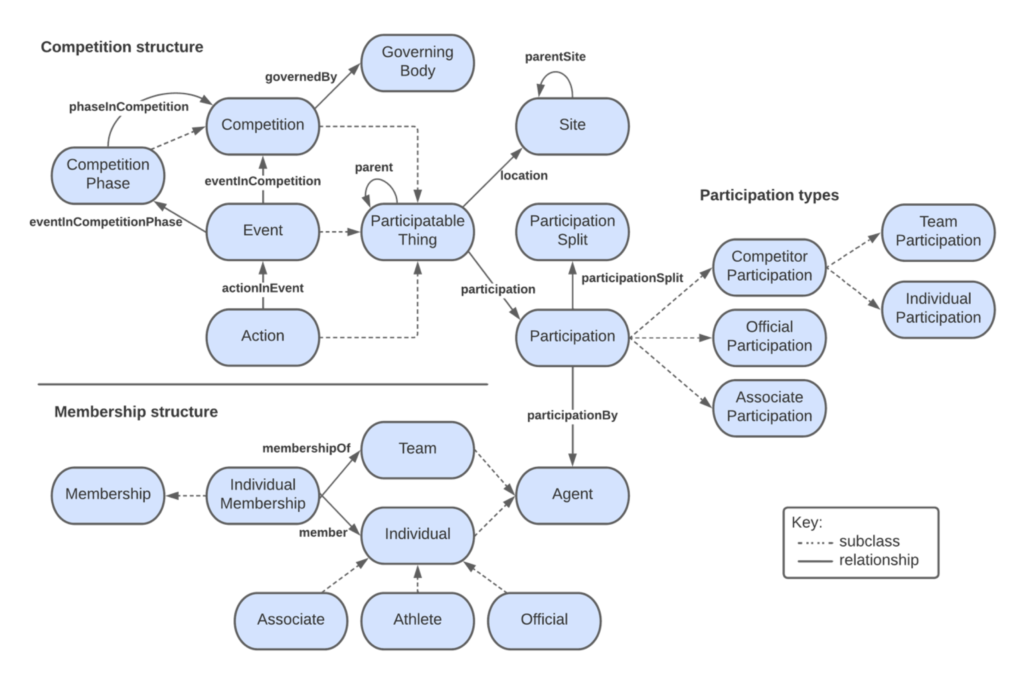
The IPTC Sports Content Working Group is happy to announce the release of IPTC Sport Schema version 1.0.
The first new IPTC standard to be released in more than 10 years, IPTC Sport Schema is a comprehensive model for the storage, transmission and querying of sports data. It has been tested on real-world use cases that are common in any newsroom or sports organisation.
IPTC Sport Schema has evolved from its predecessor SportsML. In contrast to the document-oriented nature of SportsML, IPTC Sport Schema takes a data-centric approach which is better suited to systems dealing with large volumes of data and also helps with integration across data sets.
“We reached out to many companies dealing with sports content and built up a clear picture of their needs,” says IPTC Sports Content Working Group lead Paul Kelly. “They wanted up-to-date formats, easy querying, the ability to handle e-sports and the ability to cross-reference between different media and data silos. IPTC Sport Schema addresses those requirements with a new basic model at the abstract end, and adhering to common use cases to keep things grounded.”
Content in Sports Schema is represented in the W3C’s universal Resource Description Framework (RDF), which renders any kind of data as a triple in the form of subject->predicate->object. Each component of a Sports Schema triple has a reference to an ontology, which defines the model at the heart of the standard. Querying is done using the W3C’s SPARQL standard, a kind of SQL for RDF.
“The IPTC has been working on RDF and semantic web standards for more than 10 years, going back to rNews and RightsML,” said IPTC Managing Director Brendan Quinn. “So we are very happy to release another semantic standard that can help organisations to publish and share sports data in a vendor-neutral, interoperable way.”
Being RDF-based, IPTC Sport Schema can be rendered in XML, JSON and the simple Turtle format, and can be converted easily between all three formats using free tools such as Apache Jena.
“Those familiar with SportsML or SportsJS should recognise the basic components of Sport Schema,” says Kelly, “both in the ontology and in the sports vocabularies introduced with SportsML 3.0, which were designed specifically with semantic technologies in mind.”
To support take-up and share information about the new standard, the IPTC has created a dedicated website, sportschema.org. The site contains:
- a list of use cases which were used to help design the schema and data structures
- example instance diagrams for various sports to help understand how the model can be applied to team, individual and other types of sports
- a data dictionary comparing IPTC Sport Schema to other prominent sport schemas (SportsML, ODF, BBC Ontology, etc.)
- A detailed and comprehensive IPTC Sport Schema ontology reference showing all classes, relationships and properties.
- A tool to validate Sport Schema data using the SHACL format to ensure RDF triples adhere to the specification (equivalent to XML Schema or JSON Schema)
- A tool to covert SportsML documents to IPTC Sport Schema data
- A set of unit tests and sample data files that were used to develop and maintain Sport Schema, including a bespoke unit test framework that ensures our example SPARQL queries continue to satisfy our use cases as the model evolves.
Those wishing to try out some SPARQL queries against some sports data should visit Sport Schema’s query endpoint. It includes example queries showing how to build a team roster, league standings and more from our sample data sets.
For more information on IPTC Sport Schema, see the IPTC’s landing pages on the IPTC Sport Schema standard, the standalone site sportschema.org, or the project’s GitHub repository.
If you are interested in joining those who are working on implementing IPTC Sport Schema in your project or your organisation, we would love to hear from you. Please contact us via IPTC’s contact form.

Made with Bing Image Creator. Powered by DALL-E.
Following the IPTC’s recent announcement that Rights holders can exclude images from generative AI with IPTC Photo Metadata Standard 2023.1 , the IPTC Video Metadata Working Group is very happy to announce that the same capability now exists for video, through IPTC Video Metadata Hub version 1.5.
The “Data Mining” property has been added to this new version of IPTC Video Metadata Hub, which was approved by the IPTC Standards Committee on October 4th, 2023. Because it uses the same XMP identifier as the Photo Metadata Standard property, the existing support in the latest versions of ExifTool will also work for video files.
Therefore, adding metadata to a video file that says it should be excluded from Generative AI indexing is as simple as running this command in a terminal window:
exiftool -XMP-plus:DataMining="Prohibited for Generative AI/ML training" example-video.mp4
(Please note that this will only work in ExifTool version 12.67 and above, i.e. any version of ExifTool released after September 19, 2023)
The possible values of the Data Mining property are listed below:
| PLUS URI | Description (use exactly this text with ExifTool) |
| Unspecified – no prohibition defined | |
| Allowed | |
| Prohibited for AI/ML training | |
|
http://ns.useplus.org/ldf/vocab/DMI-PROHIBITED-GENAIMLTRAINING |
Prohibited for Generative AI/ML training |
|
http://ns.useplus.org/ldf/vocab/DMI-PROHIBITED-EXCEPTSEARCHENGINEINDEXING |
Prohibited except for search engine indexing |
| Prohibited | |
|
http://ns.useplus.org/ldf/vocab/DMI-PROHIBITED-SEECONSTRAINT |
Prohibited, see plus:OtherConstraints |
|
http://ns.useplus.org/ldf/vocab/DMI-PROHIBITED-SEEEMBEDDEDRIGHTSEXPR |
Prohibited, see iptcExt:EmbdEncRightsExpr |
|
http://ns.useplus.org/ldf/vocab/DMI-PROHIBITED-SEELINKEDRIGHTSEXPR |
Prohibited, see iptcExt:LinkedEncRightsExpr |
A corresponding new property “Other Constraints” has also been added to Video Metadata Hub v1.5. This property allows plain-text human-readable constraints to be placed on the video when using the “Prohibited, see plus:OtherConstraints” value of the Data Mining property.
The Video Metadata Hub User Guide and Video Metadata Hub Generator have also been updated to include the new Data Mining property added in version 1.5.
We look forward to seeing video tools (and particularly crawling engines for generative AI training systems) implement the new properties.
Please feel free to discuss the new version of Video Metadata Hub on the public iptc-videometadata discussion group, or contact IPTC via the Contact us form.