Categories
Archives

Following the recent announcements of Google’s signalling of generative AI content and Midjourney and Shutterstock the day after, Microsoft has now announced that it will also be signalling the provenance of content created by Microsoft’s generative AI tools such as Bing Image Creator.
Microsoft’s efforts go one step beyond those of Google and Midjourney, because they are adding the image metadata in a way that can be verified using digital certificates. This means that not only is the signal added to the image metadata, but verifiable information is added on who added the metadata and when.
As TechCrunch puts it, “Using cryptographic methods, the capabilities, scheduled to roll out in the coming months, will mark and sign AI-generated content with metadata about the origin of the image or video.”
The system uses the specification created by the Coalition for Content Provenance and Authenticity. a joint project of Project Origin and the Content Authenticity Initiative.
The 1.3 version of the C2PA Specification specifies how a C2PA Action can be used to signal provenance of Generative AI content. This uses the IPTC DigitalSourceType vocabulary – the same vocabulary used by the Google and Midjourney implementations.
This follows IPTC’s guidance on how to use the DigitalSourceType property, published earlier this month.

As a follow-up to yesterday’s news on Google using IPTC metadata to mark AI-generated content we are happy to announce that generative AI tools from Midjourney and Shutterstock will both be adopting the same guidelines.
According to a post on Google’s blog, Midjourney and Shutterstock will be using the same mechanism as Google – that is, using the IPTC “Digital Source Type” property to embed a marker that the content was created by a generative AI tool. Google will be detecting this metadata and using it to show a signal in search results that the content has been AI-generated.
A step towards implementing responsible practices for AI
We at IPTC are very excited to see this concrete implementation of our guidance on metadata for synthetic media.
We also see it as a real-world implementation of the guidelines on Responsible Practices for Synthetic Media from the Partnership on AI, and of the AI Ethical Guidelines for the Re-Use and Production of Visual Content from CEPIC, the alliance of European picture agencies. Both of these best practice guidelines emphasise the need for transparency in declaring content that was created using AI tools.
The phrase from the CEPIC transparency guidelines is “Inform users that the media or content is synthetic, through
labelling or cryptographic means, when the media created includes synthetic elements.”
The equivalent recommendation from the Partnership on AI guidelines is called indirect disclosure:
“Indirect disclosure is embedded and includes, but is not limited to, applying cryptographic provenance to synthetic outputs (such as the C2PA standard), applying traceable elements to training data and outputs, synthetic media file metadata, synthetic media pixel composition, and single-frame disclosure statements in videos”
Here is a simple, concrete way of implementing these disclosure / transparency guidelines using existing metadata standards.
Moving towards a provenance ecosystem
IPTC is also involved in efforts to embed transparency and provenance metadata in a way that can be protected using cryptography: C2PA, the Content Authenticity Initiative, and Project Origin.
C2PA provides a way of declaring the same “Digital Source Type” information in a more robust way, that can provide mechanisms to retrieve metadata even after the image was manipulated or after the metadata was stripped from the file.
However implementing C2PA technology is more complicated, and involves obtaining and managing digital certificates, among other things. Also C2PA technology has not been implemented by platforms or search engines on the display side.
In the short term, AI content creation systems can use this simple mechanism to add disclosure information to their content.
The IPTC is happy to help any other parties to implement these metadata signals: please contact IPTC via the Contact Us form.
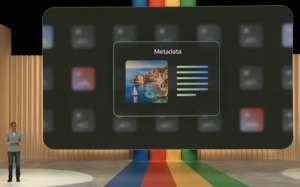
At today’s Google I/O event keynote, Sundar Pichai, CEO of Google, explained how Google will be using embedded IPTC image metadata to signal visual media created by generative AI models.
“Moving forward, we are building our models to include watermarking and other techniques from the start,” Pichai said. “If you look at a synthetic image, it’s impressive how real it looks, so you can imagine how important this is going to be in the future.
“Metadata allows content creators to associate additional context with original files, giving you more information whenever you encounter an image. We’ll ensure every one of our AI-generated images has that metadata.”
The IPTC Photo Metadata section of Google Images’ guidance on metadata has been updated with new guidance on the DigitalSourceType field:
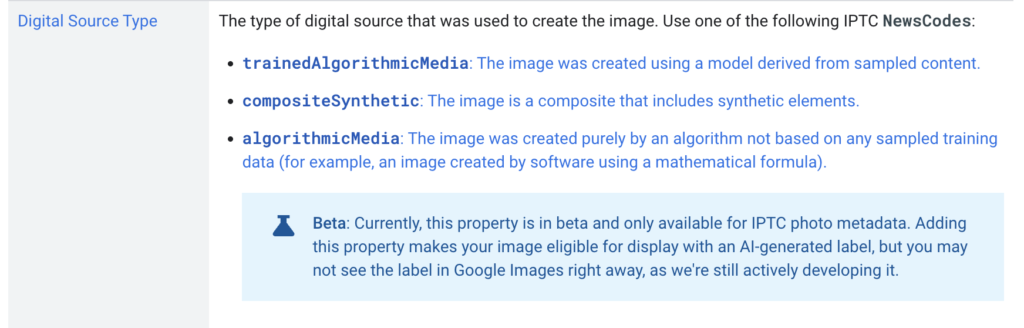
This follows the guidance on IPTC Photo Metadata for Generative AI that was recently published by IPTC.
“AI-Generated” label on Google Images
The above guidance hints at an “AI-generated label” to be used on Google Images in the future. Google recommends that all creators of AI-generated images use the IPTC Digital Source Type property to signal AI-generated content. While Google says that “you may not see the label in Google Images right away”, it appears that it will soon be available in Google Images search results.

The IPTC has updated its Photo Metadata User Guide to include some best practice guidelines for how to use embedded metadata to signal “synthetic media” content that was created by generative AI systems.
After our work in 2022 and the draft vocabulary to support synthetic media, the IPTC NewsCodes Working Group, Video Metadata Working Group and Photo Metadata Working Group worked together with several experts and organisations to come up with a definitive list of “digital source types” that includes various types of machine-generated content, or hybrid human and machine-generated media.
Since publishing the vocabulary, the work has been picked up by the Coalition for Content Provenance and Authenticity (C2PA) via the use of digitalSourceType in Actions and in the IPTC Photo and Video Metadata assertion. But the primary use case is for adding metadata to image and video files
Here is a direct link to the new section on Guidance for using Digital Source Type, including examples for how the various terms can be used to describe media created in different formats – audio, video, images and even text.
IPTC recommends that software creating images using trained AI algorithms uses the “Digital Source Type” value of “trainedAlgorithmicMedia” is added to the XMP data packet in generated image and video files. Alternatively, it may be included in a C2PA manifest as described in the IPTC assertion documentation in the C2PA specification.
The official URL for the full vocabulary is http://cv.iptc.org/newscodes/digitalsourcetype, so the complete URI for the recommended Trained Algorithmic Media term is http://cv.iptc.org/newscodes/digitalsourcetype/trainedAlgorithmicMedia.
Other terms in the vocabulary include:
- Composite with synthetic elements – https://cv.iptc.org/newscodes/digitalsourcetype/compositeSynthetic – covering a composite image that contains some synthetic and some elements captured with a camera;
- Digital Art – https://cv.iptc.org/newscodes/digitalsourcetype/digitalArt – covering art created by a human using digital tools such as a mouse or digital pencil, or computer-generated imagery (CGI) video
- Virtual recording – https://cv.iptc.org/newscodes/digitalsourcetype/virtualRecording – a recording of a virtual event which may or may not contain synthetic elements, such as a Fortnite game or a Zoom meeting
- and several other options – see the full list with examples in the IPTC Photo Metadata User Guide.
Of course, the original digital source type values covering photographs taken on a digital camera or phone (digitalCapture), scan from negative (negativeFilm), and images digitised from print (print) are also valid and may continue to be used. We have, however, retired the generic term “softwareImage” which is now deemed to be too generic. We recommend using one of the newer terms in its place.
If you are considering implementing this guidance in AI image generation software, we would love to hear about it so we can offer advice and tell others. Please contact us using the IPTC contact form.

The IPTC is very happy to announce that it has joined the Steering Committee of Project Origin, one of the industry’s key initiatives to fight misinformation online through the use of tamper-evident metadata embedded in media files.
After working with Project Origin over a number of years, and co-hosting a series of workshops during 2022, the organisation formally invited the IPTC to join the Steering Committee.
Current Steering Committee members are Microsoft, the BBC and CBC / Radio Canada. The New York Times also participates in Steering Committee meetings through its Research & Development department.
“We were very happy to co-host with Project Origin a productive series of webinars and workshops during 2022, introducing the details of C2PA technology to the news and media industry and discussing the remaining issues to drive wider adoption,” says Brendan Quinn, Managing Director of the IPTC.
C2PA, the Coalition for Content Provenance and Authenticity, took a set of requirements from both Project Origin and the Content Authenticity Initiative to create a technical means of associating media files with information on the origin and subsequent modifications of news stories and other media content.
“Project Origin’s aim is to take the ground-breaking technical specification created by C2PA and make it realistic and relevant for newsrooms around the world,” Quinn said. “This is very much in keeping with the IPTC’s mission to help media organisations to succeed by sharing best practices, creating open standards and facilitating collaboration between media and technology organisations.”
“The IPTC is a perfect partner for Project Origin as we work to connect newsrooms through secure metadata,” said Bruce MacCormack, the CBC/Radio-Canada Co-Lead.
The announcement was made at the Trusted News Initiative event held in London today, 30 March 2023, where representatives of the BBC, AFP, Microsoft, Meta and many others gathered to discuss trust, misinformation and authenticity in news media.
Learn more about Project Origin by contacting us or viewing the video below:
The IPTC has long worked with organisations on schemas for representing news and media content in all of their forms.
Back in early 2022, the IPTC started hosting the BBC Ontologies, a set of semantic web vocabularies created between 2012 and 2014 that can be used to describe news content, sports, TV and radio programmes and more. When the BBC stopped hosting them in late 2021, IPTC offered to host them on the BBC’s behalf.
“I’m very grateful to the IPTC for providing hosting for these ontologies while we perform some maintenance on their former home,” said Jeremy Tarling, Head of Content Metadata for the BBC, at the time. “For those BBC ontologies relevant to IPTC’s mission we would be keen to discuss longer-term arrangements for their hosting and ownership.”
Since then we have added the SNaP Ontology, a similar semantic web ontology created by the UK’s national news agency PA Media (known at the time as the Press Association). The SNaP ontology was similarly left without a home after the PA brand change.
“We are delighted for the SNaP Ontologies to find their home with the IPTC and its community,” said Steve Robinson, Director of Technology, PA Media Group. “It is our hope that these ontologies, complemented by other member contributions, will support the IPTC’s continued evolution of digital news standards.”
While neither of these standards are being actively developed, we at the IPTC think that they should be accessible to researchers, architects and developers in the future who may want to draw upon their concepts and vocabularies.
In fact, the BBC Sport Ontology is being used as one of the sources of inspiration for IPTC’s forthcoming sports data ontology, which will be announced soon.
With that in mind, the IPTC is willing to host other data schemas and specifications, especially those that are no longer hosted by their creators. If you have suggestions for resources that we should host in our third party area, please let us know.
The IPTC’s flagship news exchange standard, NewsML-G2, is now updated to version 2.31. The change was approved at the IPTC Standards Committee Meeting at the IPTC Autumn Meeting 2022.
The full NewsML-G2 XML Schema, NewsML-G2 Guidelines document and NewsML-G2 specification document have all now been updated.
The only change (Change Request CR00215) is that we now allow the hasInstrument element on any concept or assert. Previously we required hasInstrument to be declared on organisations only, but we realised that not every financial instrument related to an organisation: for example an exchange-traded fund, or the instrument for a commodity, do not directly relate to a specific company.
Interestingly, hasInstrument elements in <assert>s did appear to work in previous versions, but that is because of NewsML-G2’s use of the xs:any construct which allows asserts to be augmented with arbitrary elements. No validation took place on elements which were added in this way.
Examples
Example 1: hasInstrument as a child of concept
<concept> <conceptId qcode="P:18040196349" /> <type qcode="cptType:97"/> <name>Invesco Capital Appreciation Fund;R6</name> <hasInstrument symbol="OPTFX.O" type="symType:RIC" symbolsrc="symSrc:RFT"/> <hasInstrument symbol="US00141G7328" symbolsrc="symSrc:ISO" type="symType:ISIN"/> </concept>
Example 2: hasInstrument as a child of assert
<assert qcode="P:18040196349"> <name>Invesco Capital Appreciation Fund;R6</name> <type qcode="cptType:97"/> <hasInstrument symbol="OPTFX.O" type="symType:RIC" symbolsrc="symSrc:RFT"/> <hasInstrument symbol="US00141G7328" symbolsrc="symSrc:ISO" type="symType:ISIN"/> </assert>
Example 3: hasInstrument within assert/organisationDetails
This usage still works, but is now deprecated.
<assert qcode="P:18040196349"> <name>Invesco Capital Appreciation Fund;R6</name> <type qcode="cptType:97"/> <organisationDetails> <hasInstrument symbol="OPTFX.O" type="symType:RIC" symbolsrc="symSrc:RFT"/> <hasInstrument symbol="US00141G7328" symbolsrc="symSrc:ISO" type="symType:ISIN"/> <rtr:anyOtherElement> Other elements in other namespaces allowed here due to xs:any other </rtr:anyOtherElement> </organisationDetails> </assert>
- The top-level folder of the NewsML-G2 v2.31 release is http://iptc.org/std/NewsML-G2/2.31/.
- The NewsML-G2 Implementation Guidelines document, updated to cover version 2.31 is available at https://www.iptc.org/std/NewsML-G2/guidelines
- The latest NewsML-G2 Specification document is available at https://www.iptc.org/std/NewsML-G2/specification/
- The XML Schema for NewsML-G2 v2.31 is at http://iptc.org/std/NewsML-G2/2.31/specification/NewsML-G2_2.31-spec-All-Power.xsd
XML Schema documentation of version 2.31 version is available on GitHub and at http://iptc.org/std/NewsML-G2/2.31/specification/XML-Schema-Doc-Power/.
NewsML-G2 Generator updated
The NewsML-G2 Generator has been updated to use version 2.31. There are no substantive changes but the version number of generated files has been updated to 2.31.
Thanks to Dave Compton of Refinitiv (an LSE Group Company) and the NewsML-G2 Working Group for their work on the update, and to Kelvin Holland on his work on the documentation.
To follow our work on GitHub, please see the IPTC NewsML-G2 GitHub repository.
The full NewsML-G2 change log showing the Change Requests included in each new version is available at the dev.iptc.org site.

We are proud to announce that Camera Bits, Mobius Labs, Microsoft, Smithsonian, CBC and many others will be presenting at the IPTC Photo Metadata Conference next week, Thursday 10th November. With a theme of Photo Metadata in the Real World, the event is free for anyone to attend. Register here for the Zoom webinar to receive details before the event.
The event will run from 1500 UTC to 1800 UTC. The full agenda with timings is published on the event page.
We will start off with a short presentation on recent updates to the IPTC Photo Metadata Standard from David Riecks and Michael Steidl, co-leads of the IPTC Photo Metadata Working Group. This will include the new properties approved at the recent IPTC Autumn Meeting.
A session on Adoption of IPTC Accessibility properties will include speakers from Smithsonian, Camera Bits (makers of the photographers tool Photo Mechanic), Picvario presenting their progress implementing IPTC’s accessibility properties, announced at last year’s Photo Metadata Conference.
The next session will be Software Supporting the IPTC Photo Metadata Standard, where Michael Steidl and David Riecks, co-leads of the IPTC Photo Metadata Working Group, present their work on IPTC’s database of software supporting the Photo Metadata Standard, and the IPTC Interoperability tool, showing compatibility between tools for individual properties.
Use of C2PA in real-world workflows is the topic of the next session, demonstrating progress made in implementing C2PA technology to make images and video tamper-evident and to establish a provenance trail for creative works. Speakers include Nigel Earnshaw and Charlie Halford from the BBC, David Beaulieu and Jonathan Dupras from CBC/Radio Canada, Jay Li from Microsoft, and a speaker yet to be confirmed from the Content Authenticity Initiative.
The next session should be very exciting: Metadata for AI images will be the topic, featuring an introduction to synthetic media and “generative AI” images, including copyright and ownership issues behind the images used to train the machine learning models involved, from Brendan Quinn and Mark Milstein.
Then we have a panel session: How should IPTC support AI and generative models in the future? Questions to be covered include whether we should identify which tool, text prompt and/or model was used to create a generative image? Should we include a flag that indicates content was created using a “green”, copyright-cleared set of training images? And perhaps other questions too – please come along to ask your own questions! Speakers include Dmitry Shironosov, Everypixel / Dowel.ai / Synthetics.media, Martin Roberts from Mobius Labs and Sylvie Fodor from CEPIC. The session will be moderated by Mark Milstein from vAIsual.
Last year we had over 200 registrants and very lively discussions. We look forward to even more exciting presentations and discussions this time around! See you there. (Please don’t forget to register!)

The IPTC Photo Metadata Working Group is proud to announce the IPTC Photo Metadata Conference 2022. The event will be held online on Thursday November 10th from 15.00 – 18.00 UTC.
This year the theme is Photo Metadata in the Real World. After introducing two new developments last year: the IPTC Accessibility properties and the C2PA specification for embedding provenance data in photo and video content – we re-visit both technologies to see how they are being adopted by software systems, publishers and broadcasters around the world.
The 3-hour meeting will host four sessions:
- Adoption of the IPTC Accessibility Properties – we hear from vendors and content creators on how they are progressing in implementing the new properties to support accessibility
- Software Supporting the IPTC Photo Metadata Standard – showcasing an update to IPTC’s directory of software supporting the IPTC Photo Metadata Standard, including field-by-field reference tables letting users compare software implementations
- Use of C2PA in real workflows – showcasing early work on implementing the C2PA specification in media organisations
- Artificial Intelligence and metadata – looking at the questions around copyright and synthetic media: for example, when generative AI uses thousands of potentially copyrighted images to train machine learning models, who owns the resulting images?
We look forward to welcoming all interested parties to the conference – no IPTC membership is needed to attend. The event will be held as a Zoom webinar.
Please see more information and the Zoom registration link on the event page.
See you there on the November 10th!
Anyone who has managed photo metadata can attest that it is often difficult to know which metadata properties to use for different purposes. It is especially tricky to know how to tag consistently across different metadata standards. For example, how should a copyright notice be expressed in Exif, IPTC Photo Metadata and schema.org metadata?
For software vendors wanting to build accurate mapping into their tools to make life easier for their customers, it’s no easier. For a while, a document created by a consortium of vendors known as the Metadata Working Group solved some of the problems, but the MWG Guidelines are no longer available online.
To solve this problem, the IPTC collaborated with Exif experts at CIPA, the camera products industry group that maintains the Exif standard. We also spoke with the team behind schema.org. Based on these conversations, we created a document that describes how to map properties between these formats. The aim is to remove any ambiguity regarding which IPTC Photo Metadata properties are semantically equivalent to Exif tags and schema.org properties.
Generally, Exif tags and IPTC Photo Metadata properties represent different things: Exif mainly represents the technical data around capturing an image, while IPTC focuses on describing the image and its administrative and rights metadata, and schema.org covers expressing metadata in a web page. However, quite a few properties are shared by all standards, such as who is the Creator of the image, the free-text description of what the image shows, or the date when the image was taken. Therefore it is highly recommended to have the same value in the corresponding fields of the different standards.
The IPTC Photo Metadata Mapping Guidelines outlines the 17 IPTC Photo Metadata Standard properties with corresponding fields in Exif and/or Schema.org. Further short textual notes help to implement these mappings correctly.
The intended audience of the document is those managing the use of photo metadata in businesses and the makers of software that handles photo metadata.The IPTC Photo Metadata Mapping Guidelines document can be accessed on the iptc.org website. We encourage IPTC members to provide feedback through the usual channels, and non-members to respond with feedback and questions on the public IPTC Photo Metadata email discussion group.